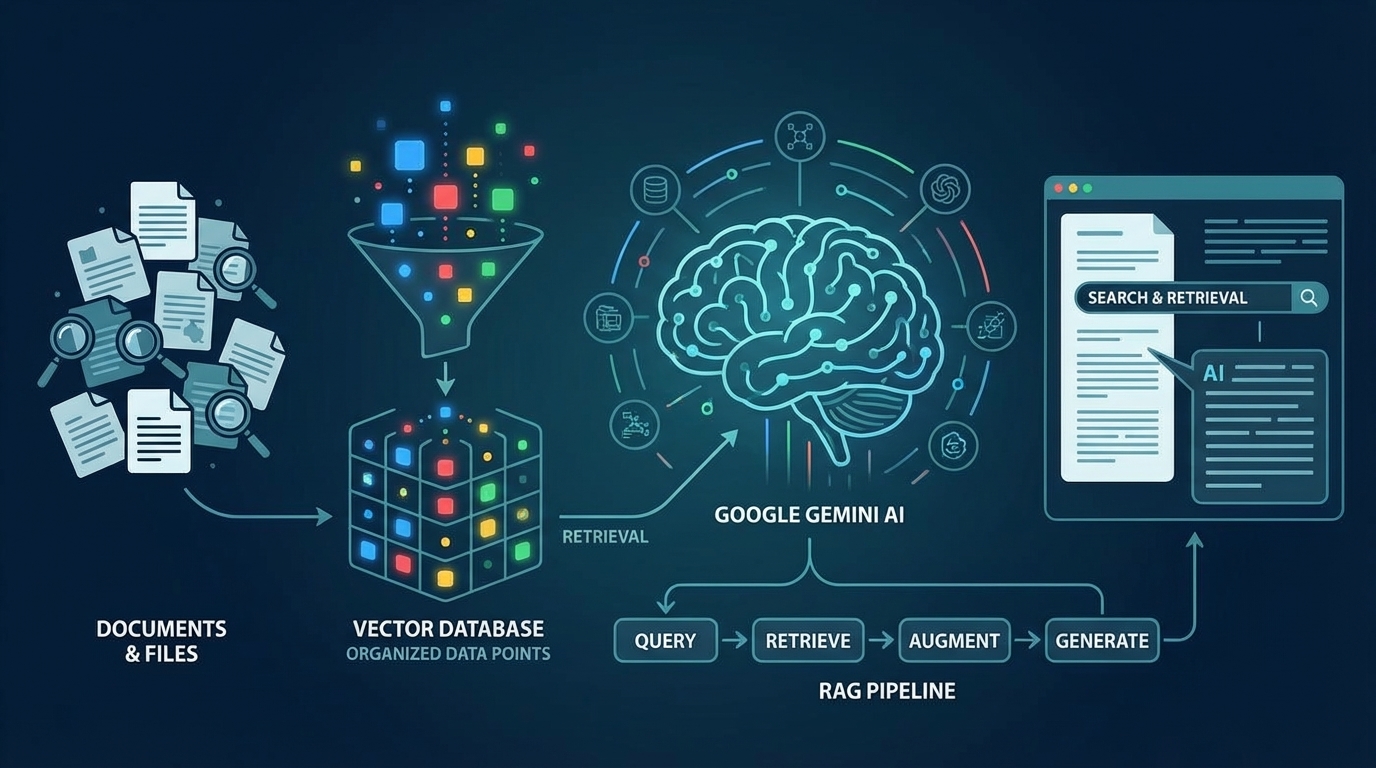
Gemini File Searchの使い方|ベクトルDB不要でRAGを構築する方法
2025年11月、GoogleはGemini APIに File Search という革新的な機能を追加しました。これは、従来RAG(Retrieval Augmented Generation:検索拡張生成)システムの構築に必要だった複雑なインフラを、APIの一機能として完全にマネージド化したものです。
「自社のドキュメントをAIに理解させたい」「社内ナレッジベースを活用したチャットボットを作りたい」――そんな要望に対して、これまでは以下のような煩雑な作業が必要でした。
関連記事: AIエージェントの基礎概念については「AIエージェントとは?従来のLLMとの違いと活用事例」をご覧ください。
- ドキュメントの前処理とチャンキング
- エンベディングモデルの選定と実行
- ベクトルデータベース(Pinecone、Weaviate、pgvectorなど)の構築・運用
- 検索ロジックの実装
- 検索結果とLLMの統合
File Searchは、これらすべてを 1つのAPIコール に集約します。本記事では、この機能の仕組みから実装方法、さらにはAIエージェントへの統合まで、実践的なコード例とともに解説します。
1. File Searchとは何か
RAGの課題を解決するマネージドソリューション
RAG(検索拡張生成)は、LLMの知識を外部データで補強する手法として広く普及しています。しかし、その実装には多くの技術的ハードルがありました。
| 従来のRAG構築 | File Search |
|---|---|
| ベクトルDB(Pinecone等)の契約・設定 | 不要 |
| エンベディングモデルの選定 | Gemini Embeddingが自動適用 |
| チャンキング戦略の設計 | デフォルト設定 or カスタマイズ可能 |
| 検索ロジックの実装 | API内蔵 |
| インフラの運用・スケーリング | Googleがフルマネージド |
File Searchは、ファイルをアップロードするだけで、自動的にチャンキング、エンベディング生成、インデックス登録を行います。クエリ時には セマンティック検索 によって関連情報を抽出し、Geminiモデルのコンテキストに注入します。
対応ファイル形式
File Searchは100種類以上のMIMEタイプをサポートしています。
ドキュメント系
- PDF、Word(.doc, .docx)、Excel(.xls, .xlsx)、PowerPoint(.pptx)
- OpenDocument形式(.odt, .ods, .odp)
テキスト・データ系
- プレーンテキスト(.txt)、Markdown(.md)、HTML
- JSON、XML、CSV、YAML
コード系
- Python、JavaScript、TypeScript、Java、Go、Rust、SQL、Dart など
各ファイルの 最大サイズは100MB です。
料金体系
File Searchの料金は非常にシンプルです。
| 項目 | 料金 |
|---|---|
| インデックス作成時のエンベディング | $0.15 / 100万トークン |
| ストレージ | 無料 |
| クエリ時のエンベディング | 無料 |
| 検索結果のトークン | 通常の入力トークン料金 |
つまり、 一度インデックスを作成すれば、その後の検索は実質無料 です(モデルの入出力トークン費用のみ)。
対応モデル
File Searchは以下のモデルで利用可能です(2025年12月時点)。
| モデル | 特徴 | 推奨用途 |
|---|---|---|
gemini-3-pro-preview |
最新・最高精度 | 複雑な推論、高精度が必要な場合 |
gemini-2.5-pro |
高精度 | 複雑なドキュメント分析 |
gemini-2.5-flash |
高速・低コスト | 一般的なRAG用途(推奨) |
gemini-2.5-flash-lite |
最軽量 | 大量リクエスト処理 |
注意:
gemini-3-flashは2025年12月時点でFile Search未対応です。Flash系で使用する場合はgemini-2.5-flashを選択してください。
2. 環境構築とセットアップ
前提条件
- Python 3.9以上
- Gemini APIキー(Google AI Studio で無料取得可能)
パッケージのインストール
pip install google-genai -U
APIキーの設定
export GOOGLE_API_KEY="your_api_key_here"
Pythonコード内で設定する場合:
from google import genai
client = genai.Client(api_key="your_api_key_here")
3. 基本的な使い方
ステップ1:File Search Storeの作成
File Search Store は、ドキュメントのエンベディングを保存するコンテナです。プロジェクトごとに最大10個のストアを作成できます。
from google import genai
client = genai.Client()
# File Search Storeを作成
store = client.file_search_stores.create(
config={'display_name': 'my_knowledge_base'}
)
print(f"Store created: {store.name}")
# 出力例: Store created: fileSearchStores/abc123xyz
ステップ2:ファイルのアップロード
作成したストアにファイルをアップロードします。アップロードは非同期で処理されるため、完了を待つポーリングが必要です。
import time
# ファイルをアップロード
operation = client.file_search_stores.upload_to_file_search_store(
file='/path/to/document.pdf',
file_search_store_name=store.name,
config={'display_name': 'company_manual'}
)
# アップロード完了を待機
while not operation.done:
print("Processing...")
time.sleep(5)
operation = client.operations.get(operation)
print("Upload completed!")
ステップ3:クエリの実行
アップロードが完了したら、自然言語でドキュメントに質問できます。
from google.genai import types
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="この会社の有給休暇制度について教えてください",
config=types.GenerateContentConfig(
tools=[
types.Tool(
file_search=types.FileSearch(
file_search_store_names=[store.name]
)
)
]
)
)
print(response.text)
Geminiは自動的に関連するドキュメントの箇所を検索し、その情報を基に回答を生成します。
4. 高度な機能
チャンキングのカスタマイズ
デフォルトでは、File Searchが自動的に最適なチャンキングを行いますが、用途に応じてカスタマイズも可能です。
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=store.name,
file='path/to/file.txt',
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200, # チャンクあたりの最大トークン数
'max_overlap_tokens': 20 # チャンク間のオーバーラップ
}
}
}
)
チャンキング戦略のポイント
- 短いチャンク(100-200トークン):精度重視。特定の情報を正確に取得したい場合に有効
- 長いチャンク(500-1000トークン):文脈重視。前後の文脈を含めて理解したい場合に有効
- オーバーラップ:チャンク境界で情報が分断されるのを防ぐ
メタデータフィルタリング
大量のドキュメントがある場合、メタデータを使って検索対象を絞り込めます。
# メタデータ付きでファイルをアップロード
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=store.name,
file='path/to/file.txt',
config={
'display_name': 'Q4_report',
'metadata': {
'department': 'sales',
'year': '2025',
'quarter': 'Q4'
}
}
)
クエリ時にフィルタを適用:
# 複雑な分析には gemini-3-pro-preview を使用
response = client.models.generate_content(
model="gemini-3-pro-preview", # 高精度モデル
contents="売上の傾向を分析してください",
config=types.GenerateContentConfig(
tools=[
types.Tool(
file_search=types.FileSearch(
file_search_store_names=[store.name],
metadata_filter={
'department': 'sales',
'year': '2025'
}
)
)
]
)
)
引用(Citation)機能
File Searchの重要な特徴として、回答に 引用情報 が自動的に付与される点があります。これにより、AIの回答がどのドキュメントのどの部分に基づいているかを検証できます。
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="製品の保証期間は何年ですか?",
config=types.GenerateContentConfig(
tools=[
types.Tool(
file_search=types.FileSearch(
file_search_store_names=[store.name]
)
)
]
)
)
# 引用情報を取得
if response.candidates[0].grounding_metadata:
for chunk in response.candidates[0].grounding_metadata.grounding_chunks:
print(f"Source: {chunk.file_search_chunk.file_name}")
print(f"Content: {chunk.file_search_chunk.content}")
5. AIエージェントへの統合
File Searchの真価は、AIエージェントと組み合わせることで発揮されます。ここでは、社内ドキュメントを参照しながら質問に答える ナレッジアシスタント を実装します。
シンプルなRAGエージェント
from google import genai
from google.genai import types
import json
class KnowledgeAgent:
def __init__(self, store_name: str):
self.client = genai.Client()
self.store_name = store_name
self.conversation_history = []
def ask(self, question: str) -> str:
"""質問に対して、ドキュメントを参照しながら回答する"""
# 会話履歴を含めたプロンプトを構築
messages = self.conversation_history + [question]
response = self.client.models.generate_content(
model="gemini-2.5-flash",
contents=messages,
config=types.GenerateContentConfig(
system_instruction="""あなたは社内ドキュメントに基づいて質問に答えるアシスタントです。
以下のルールに従ってください:
1. 回答は必ずドキュメントの情報に基づくこと
2. ドキュメントに情報がない場合は「情報が見つかりませんでした」と答えること
3. 回答には参照したドキュメント名を含めること""",
tools=[
types.Tool(
file_search=types.FileSearch(
file_search_store_names=[self.store_name]
)
)
]
)
)
answer = response.text
# 会話履歴を更新
self.conversation_history.append(question)
self.conversation_history.append(answer)
return answer
def clear_history(self):
"""会話履歴をクリア"""
self.conversation_history = []
# 使用例
agent = KnowledgeAgent(store_name="fileSearchStores/your_store_id")
print(agent.ask("新入社員の研修期間は何日ですか?"))
print(agent.ask("その間の給与はどうなりますか?")) # 文脈を維持
複数ツールを持つエージェント
File Searchを他のツール(コード実行、Web検索など)と組み合わせることで、より高度なエージェントを構築できます。
from google import genai
from google.genai import types
def create_multi_tool_agent(store_name: str):
"""複数のツールを持つエージェントを作成"""
client = genai.Client()
# ツールの定義
tools = [
# File Search(ドキュメント検索)
types.Tool(
file_search=types.FileSearch(
file_search_store_names=[store_name]
)
),
# Code Execution(コード実行)
types.Tool(
code_execution=types.CodeExecution()
),
# Google Search(Web検索)
types.Tool(
google_search=types.GoogleSearch()
)
]
def ask(question: str) -> str:
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=question,
config=types.GenerateContentConfig(
system_instruction="""あなたは多機能アシスタントです。
- 社内ドキュメントの質問にはFile Searchを使用
- 計算や分析にはCode Executionを使用
- 最新情報が必要な場合はGoogle Searchを使用
適切なツールを選択して回答してください。""",
tools=tools
)
)
return response.text
return ask
# 使用例
agent = create_multi_tool_agent("fileSearchStores/your_store_id")
# ドキュメント検索
print(agent("昨年度の売上目標達成率は?"))
# 計算を含む質問
print(agent("売上データをグラフ化してください"))
# 最新情報が必要な質問
print(agent("競合他社の最新ニュースは?"))
6. Agent Development Kit(ADK)との連携
GoogleのAgent Development Kit(ADK)は、AIエージェント開発のためのオープンソースフレームワークです。File Searchをカスタムツールとして統合することで、より構造化されたエージェントを構築できます。
ADKのインストール
pip install google-adk
File Searchツールの定義
from google.adk import Agent, Tool
from google import genai
from google.genai import types
# File Searchをラップするカスタムツール
class DocumentSearchTool(Tool):
name = "document_search"
description = "社内ドキュメントから情報を検索します"
def __init__(self, store_name: str):
self.client = genai.Client()
self.store_name = store_name
def run(self, query: str) -> str:
response = self.client.models.generate_content(
model="gemini-2.5-flash",
contents=f"以下の質問に対して、関連する情報を検索してください: {query}",
config=types.GenerateContentConfig(
tools=[
types.Tool(
file_search=types.FileSearch(
file_search_store_names=[self.store_name]
)
)
]
)
)
return response.text
# エージェントの構築
agent = Agent(
name="knowledge_assistant",
model="gemini-2.5-flash",
tools=[DocumentSearchTool(store_name="fileSearchStores/your_store_id")],
instruction="あなたは社内ナレッジを活用するアシスタントです。"
)
# 実行
result = agent.run("来月の全社会議の日程は?")
print(result)
7. ベストプラクティスと注意点
パフォーマンス最適化
-
モデル選択:ほとんどのケースで
gemini-2.5-flashが最適(高速・低コスト)。複雑な推論が必要な場合はgemini-3-pro-preview(最新・最高精度)を使用 -
ストアの分割:1つのストアを20GB未満に抑える。トピックごとにストアを分割することで検索精度も向上
-
チャンキング調整:FAQ的な用途には短いチャンク、ドキュメント理解には長いチャンクを設定
制限事項
| 項目 | 制限値 |
|---|---|
| ファイルサイズ | 100MB / ファイル |
| ストア数 | 10 / プロジェクト |
| ストレージ容量(無料) | 1GB |
| ストレージ容量(Tier 3) | 1TB |
セキュリティ考慮事項
- File Search Storeに保存されたデータはGoogleのインフラ上で管理されます
- 機密情報を扱う場合は、適切なアクセス制御とデータ分類を行ってください
- Files APIでアップロードされた生ファイルは48時間で自動削除されますが、ストア内のエンベディングは永続化されます
8. よくある質問(FAQ)
Q. Gemini File Searchは無料で使えますか?
A. ストレージとクエリは無料です。 課金が発生するのはインデックス作成時のエンベディング生成のみで、$0.15/100万トークンです。100ページのPDF 10ファイルでも約11円程度です。
Q. どのファイル形式に対応していますか?
A. 100種類以上のファイル形式に対応しています。 主な形式はPDF、Word(.docx)、Excel(.xlsx)、PowerPoint(.pptx)、テキスト、Markdown、HTML、JSON、Python、JavaScriptなどです。各ファイルの最大サイズは100MBです。
Q. ベクトルデータベースは本当に不要ですか?
A. はい、完全に不要です。 File Searchはフルマネージド型RAGシステムで、チャンキング、エンベディング生成、ベクトル検索、インデックス管理をすべてGoogleが行います。開発者はファイルをアップロードしてクエリを投げるだけです。
Q. アップロードしたファイルは削除されますか?
A. 生ファイルは48時間で削除されますが、エンベディングは永続化されます。 Files APIでアップロードされた元ファイルは48時間後に自動削除されますが、File Search Store内のエンベディング(検索用データ)は明示的に削除するまで保持されます。
Q. gemini-3-flashでFile Searchは使えますか?
A. 2025年12月時点では未対応です。 File Searchに対応しているのは gemini-3-pro-preview、gemini-2.5-pro、gemini-2.5-flash、gemini-2.5-flash-lite です。Flash系を使う場合は gemini-2.5-flash を選択してください。
Q. 日本語のドキュメントでも使えますか?
A. はい、日本語に対応しています。 Geminiのエンベディングモデルは多言語対応しており、日本語のPDFやWord文書も正確にセマンティック検索できます。
9. まとめ
Gemini File Searchは、RAG実装の 民主化 をもたらす機能です。
- インフラ不要:ベクトルDBの構築・運用が不要
- 低コスト:ストレージとクエリ時のエンベディングが無料
- 高精度:Googleの最新エンベディングモデルを自動適用
- 統合性:既存のGemini APIとシームレスに連携
これまでRAGは「やりたいけど難しい」技術でしたが、File Searchによって「すぐに試せる」技術へと変わりました。
ぜひ、あなたのプロジェクトでも活用してみてください。
参考リソース
- Gemini API File Search 公式ドキュメント
- Google AI Studio
- Agent Development Kit (ADK)
- Gemini API Cookbook(GitHub)
更新履歴
| 更新日 | 内容 |
|---|---|
| 2025-12-22 | 初版公開 |
ご注意: 本記事は2025年12月時点の情報に基づいています。APIの仕様や料金は変更される可能性がありますので、最新情報は公式ドキュメントをご確認ください。